 그래프(Graph)란?
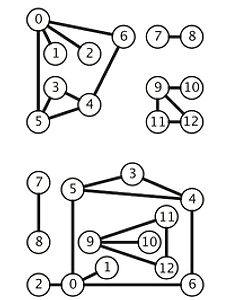
그래프(Graph)란, 다음의 2가지 요소로 구성된 자료구조이다. 1. vertex(혹은 node)의 집합2. vertex 쌍을 잇는 각 edge(간선)들의 모음 그래프에 V개의 vertex가 있을 때, 각 vertex는 0부터 V-1까지의 숫자로 이름 붙인다. 각 vertex를 잇는 edge는 v-w 혹은 (v,w)와 같이 표현한다. 그래프는 단지 vertex들의 집합과 edge들의 모음일 뿐이라는 것을 기억한다면, 위의 두 그래프는 완전히 동일하다는 것을 알 수 있을 것이다. 그래프 개념은 실생활의 많은 곳에서 사용되는데, 지도, 웹 상의 링크, 전자회로, 스케줄링, 전자상거래, 매칭, 컴퓨터 네트워크, 소셜 네트워크 등에 폭넓게 적용된다. 적용 분야에 대한 자세한 내용은 여기를 참고하자. 그래프를 ..
2019. 1. 6.
그래프(Graph)란?
그래프(Graph)란, 다음의 2가지 요소로 구성된 자료구조이다. 1. vertex(혹은 node)의 집합2. vertex 쌍을 잇는 각 edge(간선)들의 모음 그래프에 V개의 vertex가 있을 때, 각 vertex는 0부터 V-1까지의 숫자로 이름 붙인다. 각 vertex를 잇는 edge는 v-w 혹은 (v,w)와 같이 표현한다. 그래프는 단지 vertex들의 집합과 edge들의 모음일 뿐이라는 것을 기억한다면, 위의 두 그래프는 완전히 동일하다는 것을 알 수 있을 것이다. 그래프 개념은 실생활의 많은 곳에서 사용되는데, 지도, 웹 상의 링크, 전자회로, 스케줄링, 전자상거래, 매칭, 컴퓨터 네트워크, 소셜 네트워크 등에 폭넓게 적용된다. 적용 분야에 대한 자세한 내용은 여기를 참고하자. 그래프를 ..
2019. 1. 6.

